Se lavori con i dati come giornalista non passerà molto tempo prima che ti imbatta nelle frasi “ dati sporchi ” o “ dati puliti ”. Le frasi coprono un’ampia gamma di problemi e una varietà di tecniche per affrontarli, quindi in questo post analizzerò esattamente ciò che rende i dati “sporchi” e le diverse strategie di pulizia che un giornalista potrebbe adottare nell’affrontarli.
Sommario
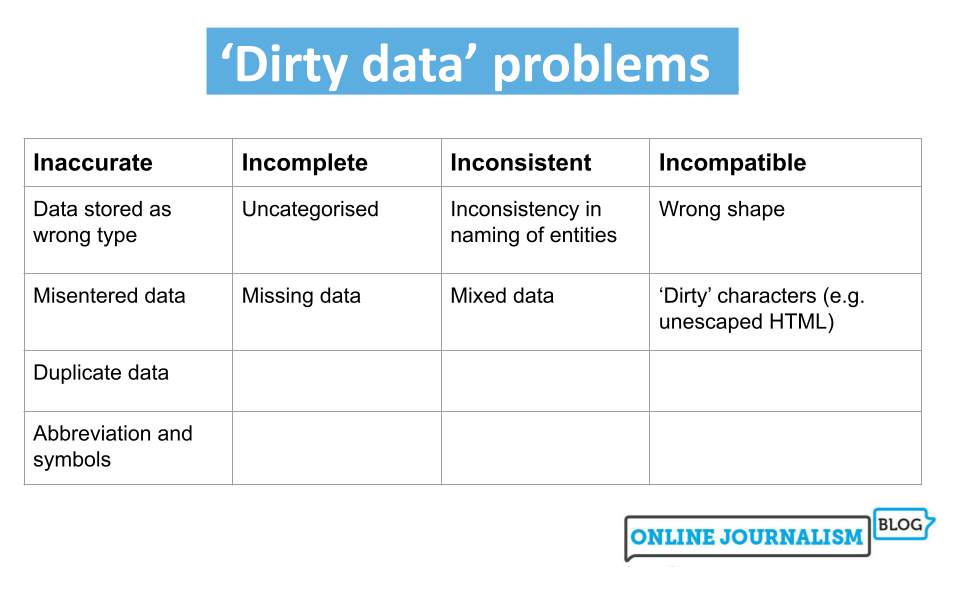
Quattro categorie di problemi relativi ai dati sporchi
Cercate le definizioni di dati sporchi e appariranno le stesse tre parole: inaccurato, incompleto o incoerente.
I dati imprecisi includono informazioni duplicate o inserite in modo errato oppure dati archiviati con il tipo di dati errato.
I dati incompleti potrebbero coprire solo particolari periodi di tempo, aree o categorie specifiche o essere del tutto privi di categorizzazione.
Dati incoerenti potrebbero denominare le stesse entità in modi diversi o mescolare insieme diversi tipi di dati.
A questi tre termini comuni ne aggiungerei anche un quarto: dati che sono semplicemente incompatibili con le domande o la visualizzazione che vogliamo eseguire con essi. Uno dei compiti di pulizia più comuni nel giornalismo dei dati, ad esempio, è ” rimodellare ” i dati da lunghi a larghi, o viceversa, in modo da poterli aggregare o filtrare in base a dimensioni particolari. (Maggiori informazioni su questo più avanti).
Individuazione e correzione: tipo di dati errato e dati inseriti in modo errato
Il primo indizio che hai dati sporchi è quando non appaiono o non si comportano come ti aspetti. Chiunque importi i dati sui fermi e sulle perquisizioni dal portale dei dati della polizia del Regno Unito in Excel, ad esempio, potrebbe notare che una delle categorie nella colonna dell’età appare come “ottobre-2017”. Perché dovrebbe essere una categoria di età?
La risposta è no: è Excel che interpreta “10-17” come una data. (Nel 2020 gli scienziati sono arrivati al punto di rinominare i geni umani per evitare questo problema comune che si stima abbia influenzato centinaia di ricerche). Oppure potresti cercare di abbinare i numeri dell’azienda e scoprire che alcuni non funzionano come dovrebbero.
Ciò potrebbe essere dovuto al fatto che codici come i numeri aziendali verranno spesso memorizzati come numeri numerici dai fogli di calcolo, con il risultato che eventuali zeri nella parte anteriore verranno eliminati. Quegli zeri sono importanti: il numero di un’azienda, a quanto pare, non è un numero, ma un codice.
Il problema in entrambi i casi è che i dati vengano archiviati come del tipo sbagliato e questo è qualcosa da cercare sistematicamente ogni volta che si importano o si aprono dati procedendo come segue:
Guarda in ogni colonna per verificare che tutte le voci siano allineate come ti aspetteresti. Excel allineerà i valori numerici (comprese le date) a destra e il testo a sinistra. Se i dati non sono allineati come dovrebbero essere (i numeri dell’azienda dovrebbero essere allineati a sinistra e le date a destra), allora hai dati sporchi.
Ordina la colonna (ascendente e discendente): il testo viene ordinato in modo diverso dai numeri, quindi l’ordinamento aiuterà a far emergere eventuali valori imprevisti. Se hai una colonna con un mix di numeri e testo, i numeri verranno ordinati prima del testo (e viceversa se ordini in modo discendente).
Aggiungi una colonna di convalida dei dati : funzioni come ISNUMBER e ISTEXT restituiranno TRUEo FALSEa seconda che la cella specificata contenga quel tipo di dati: ad esempio =ISNUMBER(A2)ti darà TRUEse A2 contiene un numero e FALSEse no. Puoi ripetere la formula su una nuova colonna per ottenere un risultato per ogni cella nella colonna vicina che stai controllando.
Aggiungi una colonna di misurazione dei dati : utile è anche la funzione LEN per dirti quanti caratteri ci sono in una cella (compresi gli spazi) permettendoti di ordinarli nuovamente in base a questo per portare dati di lunghezza imprevista (come codici che non sono coerenti) a la cima.
L’ordinamento ti aiuterà a raccogliere tutti i dati sporchi insieme per pulirli, sia manualmente per un numero limitato di errori, sia utilizzando Trova e sostituisci per pulire uno o due errori su scala più ampia o caratteri problematici come i simboli di valuta. Problemi più complessi potrebbero richiedere la creazione di formule nel foglio di calcolo per, ad esempio, sostituire gli zeri mancanti, sostituire “migliaia” con “000”, rimuovere caratteri non stampabili o convertire formati di data.
Quando si ordina una colonna, prestare attenzione anche ai numeri che sono molto più grandi o più piccoli del resto che potrebbero realisticamente essere stati inseriti in modo errato (ad esempio, manca una cifra decimale). In tal caso, potresti contattare la fonte per verificare se la cifra specifica è corretta.
Prima di correggere eventuali dati sporchi, ricordati di formattare il tipo di dati dell’intera colonna per evitare che si ripeta: per fare ciò, fai clic con il tasto destro sulla colonna e seleziona Formato celle. Quindi scegli il tipo di dati appropriato.
Fogli Google ha funzionalità di formattazione simili, oltre a una nuova opzione di pulizia dei dati (nel menu Dati ) che rimuoverà i duplicati.
Individuazione e correzione di dati incoerenti
A volte le entità in un set di dati vengono denominate in modo incoerente: una caffetteria potrebbe essere denominata Starbucks in una riga, ma Starbucks Coffee in un’altra e Starbucks Coffee Ltd in un’altra ancora.
Ciò può causare problemi se vogliamo eseguire una qualche forma di analisi aggregata che le tratti tutte come la stessa entità (questo problema diventa spesso evidente quando si crea una tabella pivot: entità con nomi simili occuperanno righe separate quando vogliamo che vengano contate tutte insieme ).
Uno dei migliori strumenti per affrontare questo problema è Open Refine e il suo strumento “Cluster e modifica”: questo raggrupperà voci simili in una colonna utilizzando uno dei numerosi algoritmi: potresti chiedergli di raggruppare nomi dal suono simile utilizzando l’algoritmo dell'”impronta digitale fonetica”; o parole che condividono la maggior parte degli stessi caratteri utilizzando l’algoritmo “impronta digitale N-gram”.
Non è necessario comprendere gli algoritmi: Open Refine ti presenta i cluster risultanti e puoi scegliere di pulirli in modo che tutte le voci all’interno di quel cluster siano uguali, oppure lasciarle com’erano.
Uno spazio bianco aggiuntivo, ad esempio, può far sì che il tuo foglio di calcolo tratti due entità separatamente (perché una ha uno spazio dove l’altra no). I suggerimenti per la pulizia dei dati di Fogli Google li identificheranno e li rimuoveranno per te.
L’uso incoerente delle maiuscole è un altro problema comune: questo può essere risolto con una nuova colonna che utilizza le funzioni PROPER o LOWER. Questi prenderanno il contenuto di una formula e lo formatteranno in modo coerente nel caso “corretto” (ogni parola inizia con una maiuscola) o in minuscolo. Puoi anche risolvere altri problemi, come l’utilizzo di parole diverse per la stessa cosa (“&” contro “e”, ad esempio, o “Ltd” contro “Limitato”) con Trova e sostituisci o con la funzione SOSTITUISCI.
Individuazione e correzione di dati misti
Un altro problema comune riscontrato nei set di dati è quando i dati vengono mescolati insieme nella stessa colonna. A volte questo è meno ovvio, come nel caso di una colonna di indirizzo che mescola il nome della strada con la città e il prefisso, mentre a volte è più evidente, come quando una colonna mescola categorie generali con sottocategorie.
Generalmente lo noti nel momento in cui desideri analizzare un aspetto dei dati misti e devi separarlo in qualche modo per farlo.
Il pulsante ” Testo in colonne ” di Excel è particolarmente utile per suddividere dati misti. Ciò ti consente di dividere una colonna in più colonne in base a un particolare “delimitatore”.
Ad esempio, se una colonna utilizza sempre una virgola dopo il nome della strada e prima del nome della città, puoi utilizzare la procedura guidata Testo in colonne per utilizzare quella virgola come “delimitatore” per inserirle in colonne separate. Allo stesso modo, se c’è uno spazio tra la prima e la seconda parte di un codice postale, quello spazio può essere utilizzato come delimitatore con effetti simili.
Alcuni problemi relativi ai dati misti sono così comuni che sono stati prodotti strumenti e basi di codice dedicati per affrontarli: Parserator è uno strumento online per “analizzare” gli indirizzi nei loro singoli componenti; mentreprobabilipeople è una libreria Python per l’analisi dei nomi e humaniformatè un equivalente in R.
Per sfide più grandi potresti aver bisogno della funzionalità di sfaccettatura e filtro di Open Refine (questo è particolarmente utile quando categorie e sottocategorie sono miste, ad esempio).
I fogli di calcolo formattati in modo scomodo rappresentano una sfida particolarmente comune nel reporting dei dati. I governi sono noti per pubblicare fogli di calcolo in cui le intestazioni delle colonne non si trovano nella prima riga, dove le intestazioni potrebbero essere su più righe e dove anche le celle contenenti intestazioni potrebbero essere unite.
Tutti questi fattori possono rendere difficile o impossibile ordinare e filtrare i dati oppure creare nuove colonne in grado di estrarre o convalidare tali dati.
Una buona regola pratica quando si apre un set di dati di questo tipo è:
Fai una copia del foglio di calcolo
Rimuovere eventuali righe prima delle intestazioni delle colonne
Rimuovi tutte le colonne vuote (Excel le tratterà come la fine di una tabella) e tutte le colonne che non ti servono
Se le intestazioni si trovano su più righe o celle unite, crea una riga di intestazione “pulita” in modo che i dati dell’intestazione vengano conservati, quindi elimina le vecchie righe/celle.
Open Refine è, ancora una volta, molto utile per affrontare molti di questi problemi. La sua procedura guidata di importazione ti consente di specificare se vuoi saltare qualche riga prima della riga di intestazione, se vuoi prendere intestazioni da più righe e se vuoi ignorare le righe vuote.
Dati nella “forma” sbagliata e principi del “dato ordinato”
Le tre regole dei dati ordinati di Hadley Wickham
Un inconveniente leggermente diverso si verifica quando i dati arrivano nella “forma” sbagliata. Esistono due grandi categorie di problemi di forma: i dati sono “lunghi” quando si desidera che siano “larghi” e viceversa.
Ad esempio, potresti voler creare un set di dati con una colonna che mostra i totali per ogni anno (vuoi ampliare i dati), ma i dati hanno invece una colonna “anno”, che li rende molto lunghi. In questa situazione, la creazione di una tabella pivot (con “anno” nella casella delle colonne) spesso rimodellerà i dati per te.
Una sfida più complicata si presenta quando i dati sono ampi, ad esempio avere una colonna diversa per ogni anno, e si desidera che siano lunghi per eseguire un’analisi diversa. È un po’ come fare il reverse engineering di una tabella pivot, convertendo ciascuna di quelle colonne “2018”, “2019”, “2020” e così via in valori all’interno di una colonna chiamata “anno”.
Per fare ciò è spesso necessaria una certa codifica e sia R che Python dispongono di librerie di codice dedicate a questo particolare problema. In Python puoi utilizzare le funzioni melt e pivot della libreria pandas per rimodellare da largo a lungo o viceversa; in R le funzioni pivot_longer epivot_wider del pacchetto tidyr faranno proprio questo.
Nell’esempio sopra, “anno” è una variabile, non un valore, quindi dovrebbe essere una colonna. E 2020 è un valore, non una variabile, quindi dovrebbe essere in una cella, non nel nome di una colonna. Seguire queste regole durante la creazione dei propri dati può garantire che sia facile analizzarli ed evitare molti problemi in seguito.
Prima di iniziare: hai *davvero* bisogno di pulirlo?
Un’ultima nota da fare su tutto questo: la pulizia può richiedere molto tempo, quindi non intraprendere una pulizia importante a meno che tu non sappia che hai assolutamente bisogno che i dati siano puliti come pensi.
pesso quando si lavora con i dati ci sono solo poche colonne che sono effettivamente importanti per la nostra storia, quindi potresti dedicare ore a una sfida di pulizia solo per decidere in seguito che non avevi bisogno di pulire quella colonna di dati per la storia.
Allo stesso modo, dedicare un po’ di tempo a pensare a diversi modi di affrontare la pulizia dei dati può farti risparmiare molto tempo in seguito. Strumenti come Open Refine potrebbero richiedere un po’ di tempo per essere appresi, ma spesso risparmierai quel tempo e altro ancora potendo utilizzarli invece di pulire manualmente i dati.
Usiamo cookie per ottimizzare il nostro sito web ed i nostri servizi.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.